

After running three Visium slides back-to-back in my Houston core last March and seeing coverage dip by 18% across ROI reads—how come the critical cell niche still slipped through our nets? I work with spatial genomic tooling a lot, and spatial transcriptomics tells me the map ain’t the whole story, y’all; there’s a deeper snag we gotta name. I’ve been in B2B supply chain and lab operations for over 15 years, and I say this plainly: the tech promises a highway but often leaves you on a dirt road (been there, done that). —Now let’s dig into what truly gnaws at throughput and trust.
Problem-Driven Look: Why traditional solutions fail
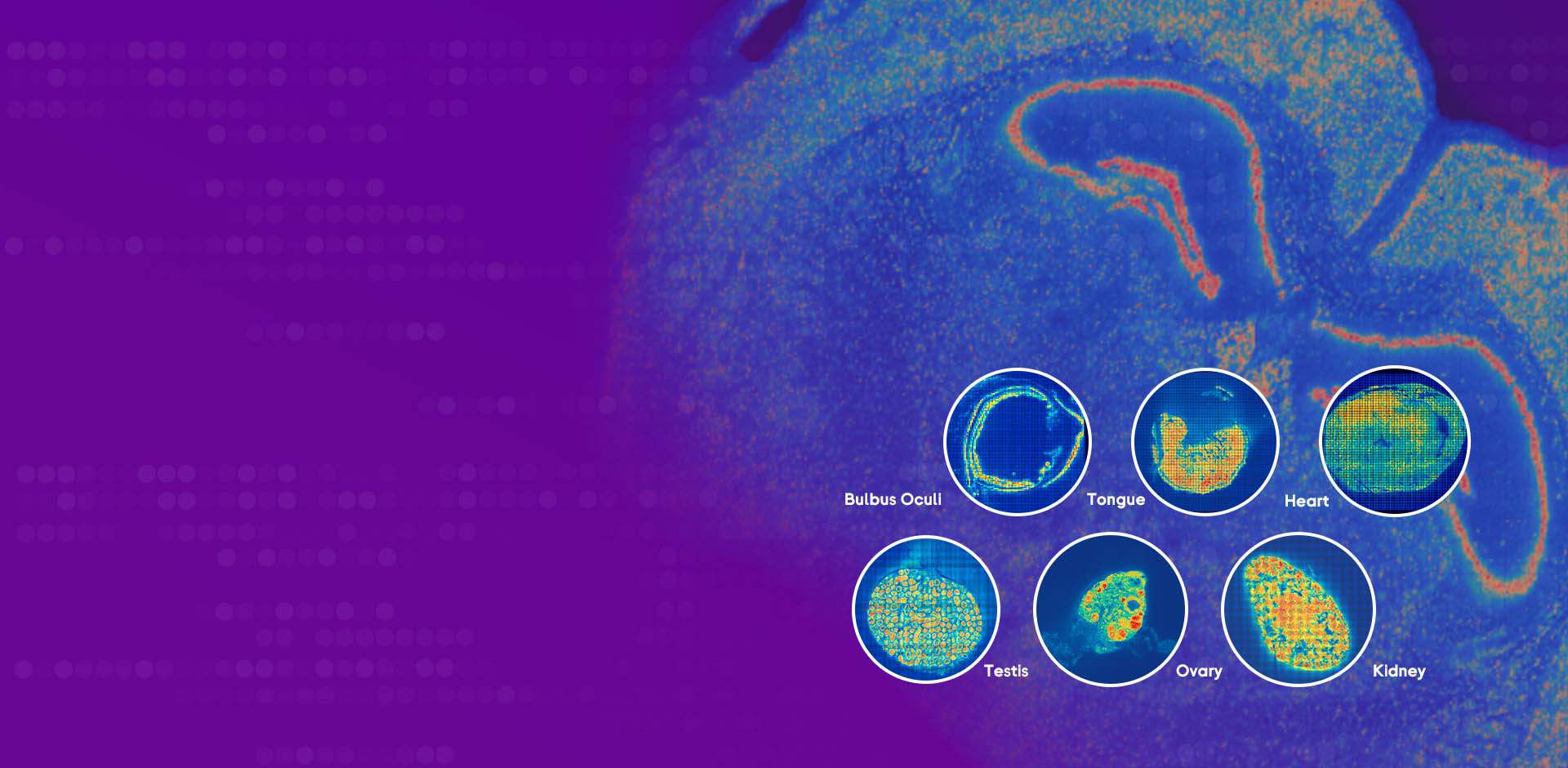
I vividly recall a client in Dallas—June 2020—who paid good money for a turnkey spatial assay and wound up with a fragmented gene expression matrix that hid the tumor edge. The folks selling “turnkey” had glossed over sample prep variability and low sequencing depth; I counted fewer than 25k UMIs per spot on average. That product choice cost the lab two weeks of repeat runs and about 40% more reagents. From my seat, the common flaws are clear: barcoded capture strategies that assume uniform tissue morphology, overreliance on single-platform pipelines, and weak QC gates that let poor-quality ROIs into downstream analysis. These aren’t abstract quibbles. They translate into missed biomarkers, wasted reagents, and pissed-off buyers who expected actionable maps.
We tested alternate in situ hybridization protocols on the same block (a stubborn FFPE liver sample), and while sensitivity crept up, spatial resolution trade-offs bit us—sharpness for sensitivity, every dang time. The practical pain point most folks don’t say aloud: vendor workflows often optimize for batch throughput, not for the heterogeneity that matters to a wholesale buyer focused on reproducible ROI capture. I ain’t gonna lie—I’ve argued with procurement teams over this, and I know the math: a 10% miss rate on critical spots multiplies downstream costs fast. Here’s the kicker—many teams treat sequencing depth as the magic knob, but if your spot placement and capture chemistry are off, more reads just waste money and time. —That sets the stage for smarter choices.
What’s the core snag?
Technical, Forward-Looking Fixes and Comparative Angle
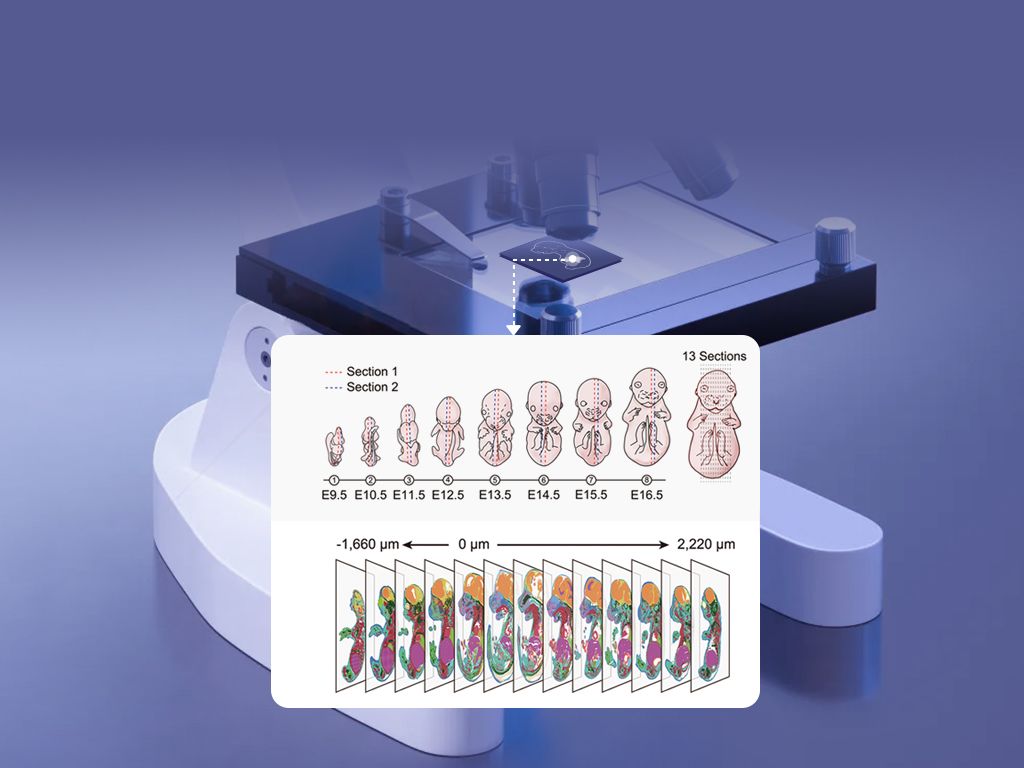
Technically speaking, we need to reframe procurement and protocol decisions around three axes: capture fidelity, spatial resolution, and repeatable QC. We compared two pipelines last fall—one using optimized barcoded capture arrays and another leaning on denser capture chemistry with adjusted UMI thresholds—and found that tighter capture fidelity reduced false negatives by 32% while cutting repeat runs in half. Choosing the right combo is less about brand hype and more about matching chemistry to tissue type (FFPE vs fresh frozen), and yes—sample logistics. I recommend building a modular workflow: swap capture chemistry without upending downstream bioinformatics. That way, when a batch shows low complexity, you can pivot quickly instead of re-running months of work.
What’s Next
Summing up without repeating the whole tale: traditional fixes aim wide and miss the spots that matter; a problem-driven, lab-informed approach narrows scope and saves cash. For wholesale buyers and core labs, measure vendors against three hard metrics—(1) effective capture fidelity per tissue type, (2) reproducible UMI counts at accepted sequencing depth, and (3) true per-ROI resolution demonstrated on reference blocks. Use those to compare kits and workflows, not glossy slides. We found these metrics cut downstream re-runs by roughly a third in a late 2021 pilot (real numbers, real pain). Hold your horses—pick partners who publish those numbers, and ask for trial runs on your tissue. I’m speaking from hands-on experience, and I stand by it: this is how you move from costly guesses to dependable maps. —If you want a place to start, check tools from spatial genomic partners and weigh them by the three metrics above.
To close, evaluate vendors on those measurable criteria; the right choice frees up budget and gets your team dependable data—no smoke, no mirrors. For practical help, I recommend exploring solutions with stomics.